基于短语的SMT这种方法和基于词的SMT有着同样的原则:统计、重新排序、在词汇上用一些技巧。
不过,它不仅要将文本分成词,还要分成短语,确切地说是n个单词的连续序列,称为n-grams。
机器就这样学会了翻译单词的稳定组合,明显提高了准确性。

这种方法有一个诀窍,所谓“短语”并不一定符合句法结构,如果有语言学知识的人干涉了句子结构,翻译的质量会大大下降。
除了准确性的提高,基于短语的SMT还为双语语料带来了更多的选择。对于基于词的方法来说,来源语料的精确匹配非常重要,要排除一切意译和自由发挥。而基于短语的方法可以用这样的语料来学习。
为了改进翻译算法,科学家们甚至开始不同语言的新闻网站。

2006年,这种方法开始普及了。Google翻译、Yandex、微软必应等等在线翻译工具都用上了基于短语的SMT,一直用到了2016年。
在这个时期,你所听到的“统计机器翻译”通常指的就是基于短语的SMT,直到2016那年,它都被视为最先进的机器翻译方法。
基于句法的SMT这个方法也应该简单提及。在神经网络出现之前的许多年里,基于句法的翻译被认为是“翻译的未来”,但这个想法并没有起作用。
基于句法翻译的支持者认为,这个方法有可能与基于规则的方法合并。这个方法是对句子进行精确的句法分析,确定主谓宾等,然后构建一个句法树。使用这种方法,机器学习在语言之间转换句法单元,并通过单词或短语翻译其余部分。
这将彻底解决字对齐问题。

问题是,句法分析的效果非常不好,尽管我们认为这件事早就被解决了似的。好几次我都尝试用句法树来解决比分析主谓宾更复杂的任务,但每次都铩羽而归。
神经机器翻译(NMT)
2014年,一篇关于在机器翻译中使用神经网络的论文对外发布。作者包括蒙特利尔大学的Kyunghyun Cho、Yoshua Bengio等人。
但这篇很有意思的论文并未引发广泛关注,除了Google——他们立刻开始动手。两年后的2016年9月,Google宣布了一个颠覆性的进展。
这就是神经机器翻译。
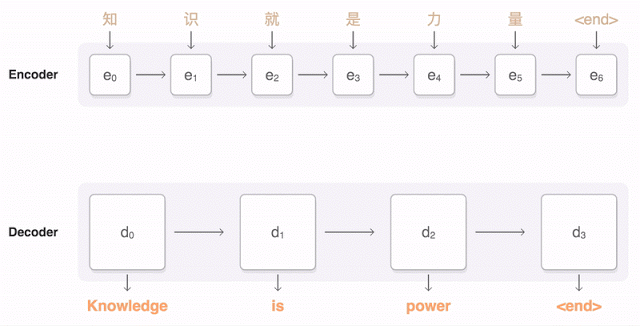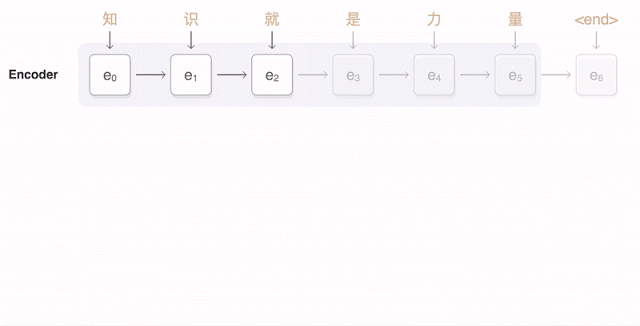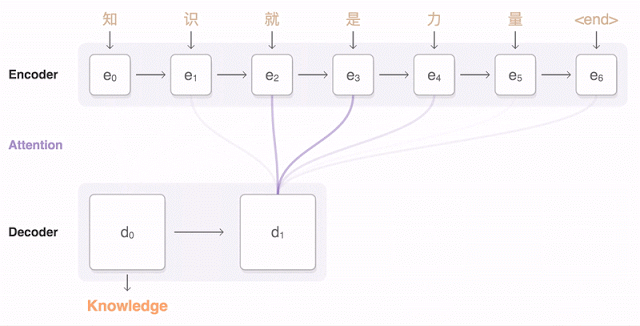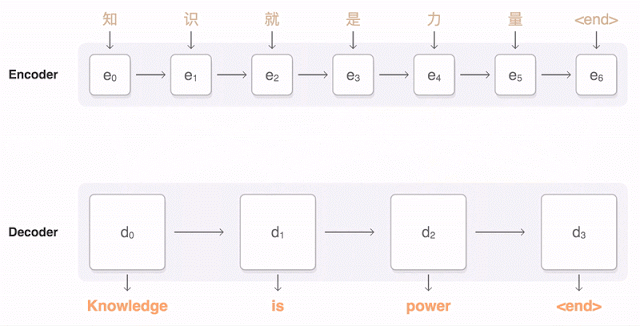
与之相关的论文,共有31位作者。Google也宣布把这个新的技术应用到Google翻译等产品之中。神经机器翻译是怎么工作的呢?
我们先从画画说起。对于一只小狗,如果能用语言准确的描述小狗的特征,即便你从来没有见过这只狗,也能根据描述画出一个类似的小狗。

翻译同理。如果可以找到一句话里的特征,也可以将一种语言的文字,翻译成另外一种语言。问题在于,怎么找到这些特征?
三十年前,科学家们已经在尝试创建通用语言代码,最后以失败告终。
但现在,我们有了深度学习,找特征的事情它最擅长。卷积神经网络CNN适合处理图片,而在文本领域,循环神经网络RNN更适合。
两年来,神经网络超过了翻译界过去几十年的一切。神经翻译的单词错误减少了50%,词汇错误减少17%,语法错误减少19%。
以前统计机器翻译的方法,始终以英语为本。如果从俄文翻译成德文,机器需要首先把俄文翻译成英文,然后再从英文翻译成德文,中间会产生两次损失。
而神经翻译不需要这样。于是,两种语言之间即便没有词典,也能互相翻译理解这件事,第一次成为可能。

Google发布的九种语言的神经机器翻译被称为GNMT。它由8个编码器和8个RNN解码器层构成,解码器网络中还有注意力连接。
这套系统还引入了众包机制。用户可以选择他们认为最正确的翻译版本,在某种程度上,这相当于帮助Google的数据打标签,以及帮助训练神经网络。
结论和未来每个人都对“巴别鱼”这个概念感到兴奋。
巴别鱼(babel fish)是科幻喜剧《银河系搭便车指南》中虚构的一种生物。巴别鱼以声音中的语言概念为食,消化后排出跟寄主同调的脑波。只要塞到耳朵里去,就可以听懂各种语言。所以,巴别鱼也成为即时语音翻译的代名词。
目前各家在这方面也有所进展。例如Google推出了Pixel Buds,而在国内网易有道、科大讯飞、搜狗等公司也都先后推出了翻译机类产品。
最近有个朋友就试用了一台最新的产品。翻译出来是这样的:

当然还有很多的进步空间。例如目前训练神经网络,都是通过一组一组的平行语料。神经网络还不能像人类一样通过自主阅读来提高翻译技能。
不过已经有人开始这方面的尝试了。比如这篇论文Word Translation Without Parallel Data,几位作者来自Facebook AI Research等机构。

期待更多的进展出现。





